Scaling Kubernetes to Thousands of CRDs


August 11, 2022
Nic Cope
Reading time: 14 min read
Share:
Over the past few months Crossplane has pushed the boundaries of Kubernetes with the number of Custom Resources it supports. In this post we’ll explore the limitations Upbound engineers have discovered and how we’ve helped to overcome them.
Background
Upbound founded Crossplane to help you build cloud control planes. These control planes sit one level above the cloud providers and allow you to customize the APIs they expose. Platform teams use Crossplane to offer the developers they support simpler, safer, self-service interfaces to the cloud.
Crossplane uses what we call a provider to extend a control plane with support for new clouds - for example installing the AWS provider allows your control plane to wrap AWS with your own concepts and policy. A Crossplane provider extends Crossplane with support for all of the APIs that its underlying cloud provider supports. We call these APIs Managed Resources, or MRs.
MRs are the building blocks of which the APIs you define using Crossplane are composed. To build a control plane with Crossplane you:
- Define the APIs you’d like your control plane to expose.
- Install the providers you’d like to use to power those APIs.
- Teach Crossplane which MRs to create, update, or delete when someone calls your APIs.
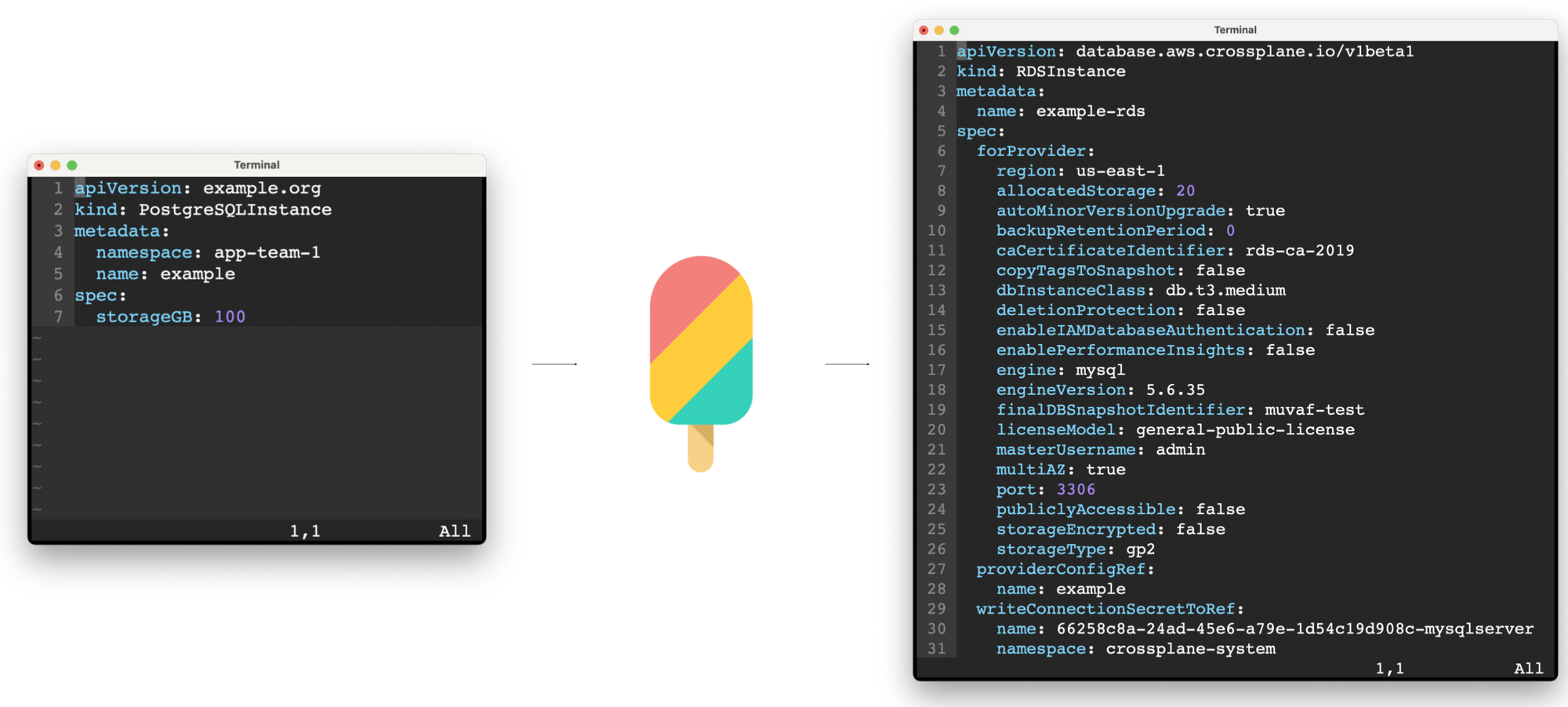
Crossplane providers aim to be high fidelity, full coverage representations of their corresponding cloud providers. At the time of writing AWS exposes around 1,000 API endpoints, which means installing an AWS provider with full coverage of the AWS API would extend Crossplane with support for around 1,000 new kinds of MR. A multi-cloud control plane that uses full coverage AWS, Azure, and GCP providers would support around 2,000 MRs. Behind the scenes, each of these MRs is defined by a Kubernetes Custom Resource Definition (CRD).
The Kubernetes API server is a key component of a Crossplane control plane. Upbound identified the strength of Kubernetes’s control plane early on and chose to build Crossplane on it. The API server offers an extensible JSON REST API with out-of-the-box support for reliable persistence (i.e. etcd) as well as useful features like Role Based Access Control (RBAC) and webhooks that can mutate or validate the data contained in an API call before it is committed to storage.
The API server distinguishes between “built in” API resources that power mostly container-focused concepts like Pods, Deployments, and Services from “Custom (API) Resources” (CRs) that may represent anything. A Crossplane MR is a kind of Kubernetes CR. The API server uses CRDs to learn about new kinds of CRs. A CRD includes all the information the API server needs to expose a new CR - for example its type and OpenAPI schema. This is a fairly novel approach; the API server exposes an API that can be called to teach it other APIs to expose.
Before Crossplane even the most advanced Kubernetes users extended their API servers with only a modest amount of CRs - perhaps creating tens of CRDs. As Crossplane began to support hundreds of MRs we began to discover limits to the number of CRDs Kubernetes could handle.
API Discovery
The issues we’ve observed can be grouped into two buckets - client-side and server-side. The client-side issues are largely contained to a process known as discovery. Clients like kubectl use this process to discover what APIs an API server supports. This allows clients - among other things - to ‘autocomplete’ API types. For example, to know that when someone types kubectl get po they probably mean kubectl get pods.
The key issue with the discovery process is that it requires a client to “walk” many of the API server’s endpoints. Custom resources are served by the API server at endpoints like:
https://example.org/apis/<group>/<version>/<kind>/<name>
For example a MR named cool-db and of kind: Instance in the rds.aws.upbound.io/v1 API group would be served at:
https://example.org/apis/rds.aws.upbound.io/v1/instances/cool-db
In order to discover that this endpoint exists a client queries:
- https://example.org/apis to get the list of supported API groups, e.g. rds.aws.upbound.io.
- https://example.org/apis/rds.aws.upbound.io to determine what versions exist within a group, e.g. v1.
- https://example.org/apis/rds.aws.upbound.io/v1 to determine what kinds of CR exist at version v1.
When there are thousands of different kinds of CR, clients have to hit a lot of API endpoints to complete the discovery process. For example the ~2,000 kinds of Crossplane MR offered by the “big three” cloud providers - AWS, Azure, and GCP - are spread across about 300 API groups and versions, meaning that clients must make around 300 HTTP requests to perform discovery. This isn’t fundamentally that bad - responses to these requests are reasonably small relative to modern network speeds and clients can leverage HTTP/2 to avoid the overhead of many TCP connections to the API server. The scaling issues we’ve seen around discovery are largely due to assumptions made by client-side rate limiters and caches.
Client-Side Rate Limits
The first client side issues we noticed made themselves quite obvious - every ten minutes kubectl’s cache of discovery results would be invalidated and it would emit logs like the following for up to 5 or 6 minutes before actually doing what you asked it to do:
Waited for 1.033772408s due to client-side throttling, not priority and fairness, request: GET:https://api.example.org/apis/pkg.crossplane.io/v1?timeout=32s
This issue was fairly straightforward to address. The part of kubectl that performs discovery uses a rate limiter to ensure it doesn’t overload the API server. When we first noticed these logs the rate limiter allowed the client to make 5 requests per second on average, with bursts of up to 100 requests.
The quick fix for this issue was to relax the rate limits. Today discovery is still limited to 5 requests per second but allows bursts of up to 300 per second. This limit was raised in kubectl in time for the v1.22 release at the request of engineers from Cruise and Upbound among others. The discovery cache was also configured to expire after 6 hours rather than 10 minutes. As of Kubernetes v1.25 all clients built on the client-go library will enjoy the raised limit.
Client-Side Cache Writes
The next client-side issue was a little tougher to diagnose. Our analysis showed that even with rate limiting completely disabled it could take almost 20 seconds to perform discovery of ~300 API groups. At first we assumed this was a network limitation - that it simply took around 20 seconds for a modern internet connection to download the discovery data. Through a stroke of good luck we noticed that it actually only took 20 seconds on macOS - on Linux it was almost instantaneous.

Fortunately kubectl has a convenient -profile flag that allows us to gain insight into where it’s spending its time. After trying a few different types of profile we noticed that the mutex profiler showed that 94% of kubectl’s time was spent inside a code path related to caching the discovery data.
We found that the diskv library kubectl uses to cache discovery data was configured to fsync all cached files - one file for each of the ~300 discovery endpoints. This system call ensures that the operating system flushes data written to a particular file all the way down to persistent storage. On macOS Go uses the F_FULLSYNC fnctl to provide a strong guarantee that data has been persisted to disk. This is apparently much slower than on other operating systems, and not recommended by Apple except where it's critical to persist data.
F_FULLFSYNC Does the same thing as fsync(2) then asks the drive to flush all buffered data to the permanent storage device (arg is ignored). This is currently implemented on HFS, MS-DOS (FAT), and Universal Disk Format (UDF) file systems. The operation may take quite a while to complete.
There’s some amount of controversy around whether Apple’s storage layer is fundamentally slower than others, or whether their hardware is simply more honest about the time required to fully persist data. Either way, the level of guarantee provided by this call is not required for a cache that can easily be recreated.
As of Kubernetes v1.25 Upbound has updated kubectl (and all client-go based clients) to guarantee the integrity of the discovery cache using checksums rather than fsyncs. Instead of trying hard to persist the cache at write time we detect and invalidate corrupt entries at read time. This approach provides similar integrity ~25x faster on macOS (it’s also ~2x faster on Linux).
Before our fix it took ~22ms to write then read a cached value:
$ go test -v -bench . -run '^Bench'
goos: darwin
goarch: arm64
pkg: k8s.io/client-go/discovery/cached/disk
BenchmarkDiskCache
BenchmarkDiskCache-10 60 22272642 ns/op
PASS
ok k8s.io/client-go/discovery/cached/disk 2.582s
After our fix it takes ~0.7ms to write then read a cached value:
$ go test -v -bench . -run '^Bench'
goos: darwin
goarch: arm64
pkg: k8s.io/client-go/discovery/cached/disk
BenchmarkDiskCache
BenchmarkDiskCache-10 1534 761469 ns/op
PASS
ok k8s.io/client-go/discovery/cached/disk 1.483s```Future Client-side Improvements
The discovery rate limits have (infamously?) been compared to the US debt ceiling - a limit that is raised every time it is hit. The current limits are just enough for Crossplane’s most intensive use cases but that won’t last long. There’s an increasing demand to remove them entirely.
The spirit of the client-side rate limits is to avoid overloading the API server with too many requests. This is intuitively a good idea, but suffers from two issues:
- Rate limiter state doesn’t persist past the lifetime of the client. Most kubectl commands complete within a second or three, so a rate limiter has a small amount of context in which to make decisions. If each kubectl command takes a second to complete a tight loop of commands would effectively be limited to 300 requests per second.
- There’s no coordination between clients - many clients all bursting to 300 requests per second at once could still overload the API server.
API Priority and Fairness (AP&F), which became a beta feature of the API server in v1.20, overcomes the above issues. It uses server-side queues and traffic shedding to protect the API server. With AP&F:
- Each API server has a configurable number of priority levels.
- RBAC-like rules classify requests to priority level by resource type, user, namespace, etc.
- Requests may be shuffle-sharded across several queues to significantly reduce the impact of noisy clients on their peers, even at the same priority level.
- Requests are served an inexpensive HTTP 429 “Too Many Requests” response when the API server is overloaded.
Work is also underway to reduce the number of HTTP requests required to perform discovery, obviating the need for rate limits. A Kubernetes Enhancement Proposal (KEP) that would add a single aggregated HTTP endpoint for discovery has been approved and is targeting alpha support in Kubernetes v1.26. With this endpoint in place clients would be able to perform discovery by hitting a single HTTP endpoint. This aggregated discovery endpoint will also support ETag based caching, allowing clients to ensure they download discovery data only when their cache is known to be stale.
OpenAPI Schema Computation
Around the same time we first saw reports of client-side rate limiting we also noticed that the Kubernetes API Server would act strangely under CRD load:
I saw all kinds of crazy errors, from etcd leaders changing to the API server reporting that there was no such kind as CustomResourceDefinition, to HTTP 401 Unauthorized despite my credentials working on subsequent requests.
Primarily we would see requests taking a long time to be served, if they were served at all. This behavior seemed to persist for up to approximately one hour after a few hundred CRDs were created.
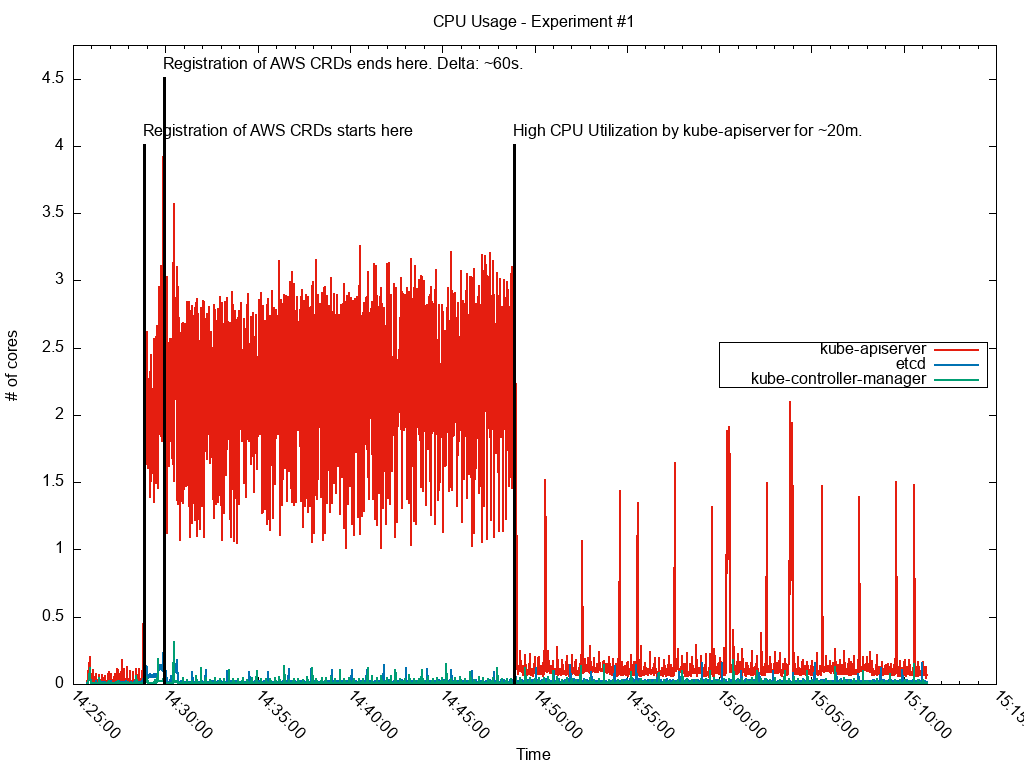
When we looked at monitoring dashboards we would see that the API server showed a period of heavy CPU utilization immediately after many CRDs were created. Interestingly, we noted that this period of elevated utilization was even longer when we added a large batch of CRDs to an API server that already had many.
Profiling the API server’s CPU utilization showed that the main offender was the logic that computes its aggregate OpenAPI v2 schema. Each time a CRD was added or updated the OpenAPI controller would:
- Build a swagger spec for the defined CR.
- Merge swagger specs of all known CRs together into one big spec.
- Serialize the giant merged spec into JSON, so it could be served by the /openapi/v2 endpoint.
That is, each time a CRD was added or updated the API server was doing serialization work that became more and more expensive as the number of CRDs increased. Adding many CRDs at once caused this to happen in a tight loop that could easily starve the API server’s CPU budget.
In this case we were lucky. After earlier reports of increased memory usage following CRD creation the API server maintainers had identified and begun work on a fix that also alleviated the CPU usage we had observed. This fix makes computation of the schema served at /openapi/v2 lazy - it defers all processing until a client actually makes a request to that API endpoint. With a little help from Upbound to bump dependencies and keep cherry-picks moving, the fix made it into Kubernetes v1.23.0 and was backported to patch releases v1.20.13, v1.21.7, and v1.22.4.
etcd Clients
With the new, more efficient approach to OpenAPI schema computation we quickly noticed the next API server-side bottleneck - persistently elevated memory utilization. In our experiments we found that the API server uses a little over 4MiB of physical (Resident Set Size, or RSS) memory per CRD.
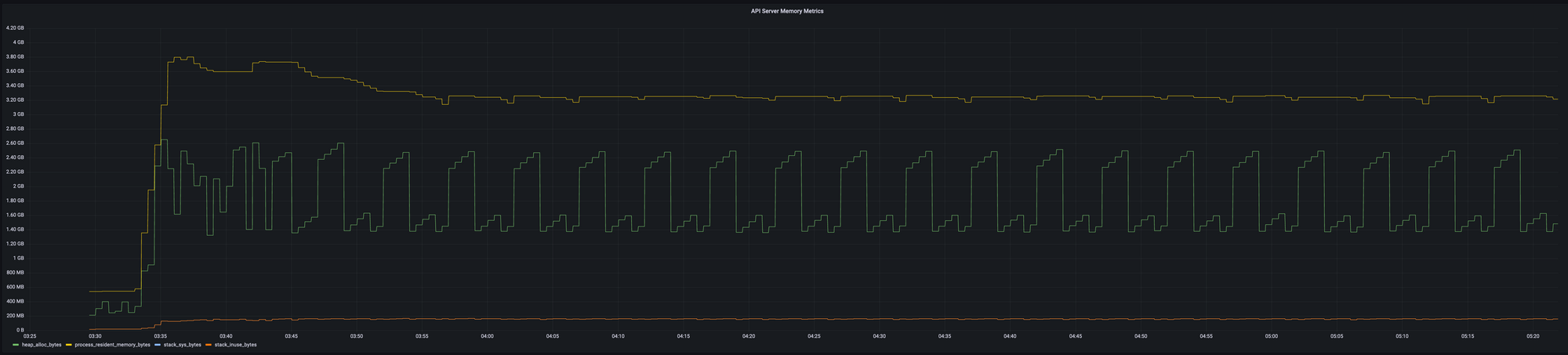
This is particularly problematic for hosted Kubernetes services like Google Kubernetes Engine (GKE), which often limit the CPU and memory available to the API server. These services can gracefully scale the API server up when they predict it will require more resources - e.g. when more nodes are created. Unfortunately at the time of writing most don’t factor in more CRDs being created and won’t begin scaling until the API server is repeatedly “OOM killed” (terminated for exceeding its memory budget).
Although it took only ~150 s for the ProviderRevision to acquire the Healthy condition, the regional GKE cluster went through the repairing mode at least three times afterwards. In between these "RUNNING" and "RECONCILING" states of the regional cluster, we have observed different kinds of errors in response to the kubectl commands run, notably connection errors and I/O timeouts while reaching the API server. It took over an hour for the cluster to stabilize. However, the control-plane was intermittently available for short periods during this period.
All the hosted Kubernetes services we’ve tested (i.e. GKE, AKS, and EKS) are affected by this issue to various extents. They all self-heal, but experience periods of API server unavailability ranging from 4-5 seconds through to an hour until they do. Note that this doesn’t stop the cluster from functioning entirely - Kubelets and containers continue to run - but it does stop all reconciliation.
Again we turned to Go’s handy built-in profiling tools, and immediately found some low-hanging fruit. It turns out that a logging library named Zap was responsible for more than 20% of in-use API server memory. Ironically Zap is explicitly designed for low overhead, but was accidentally being misused.
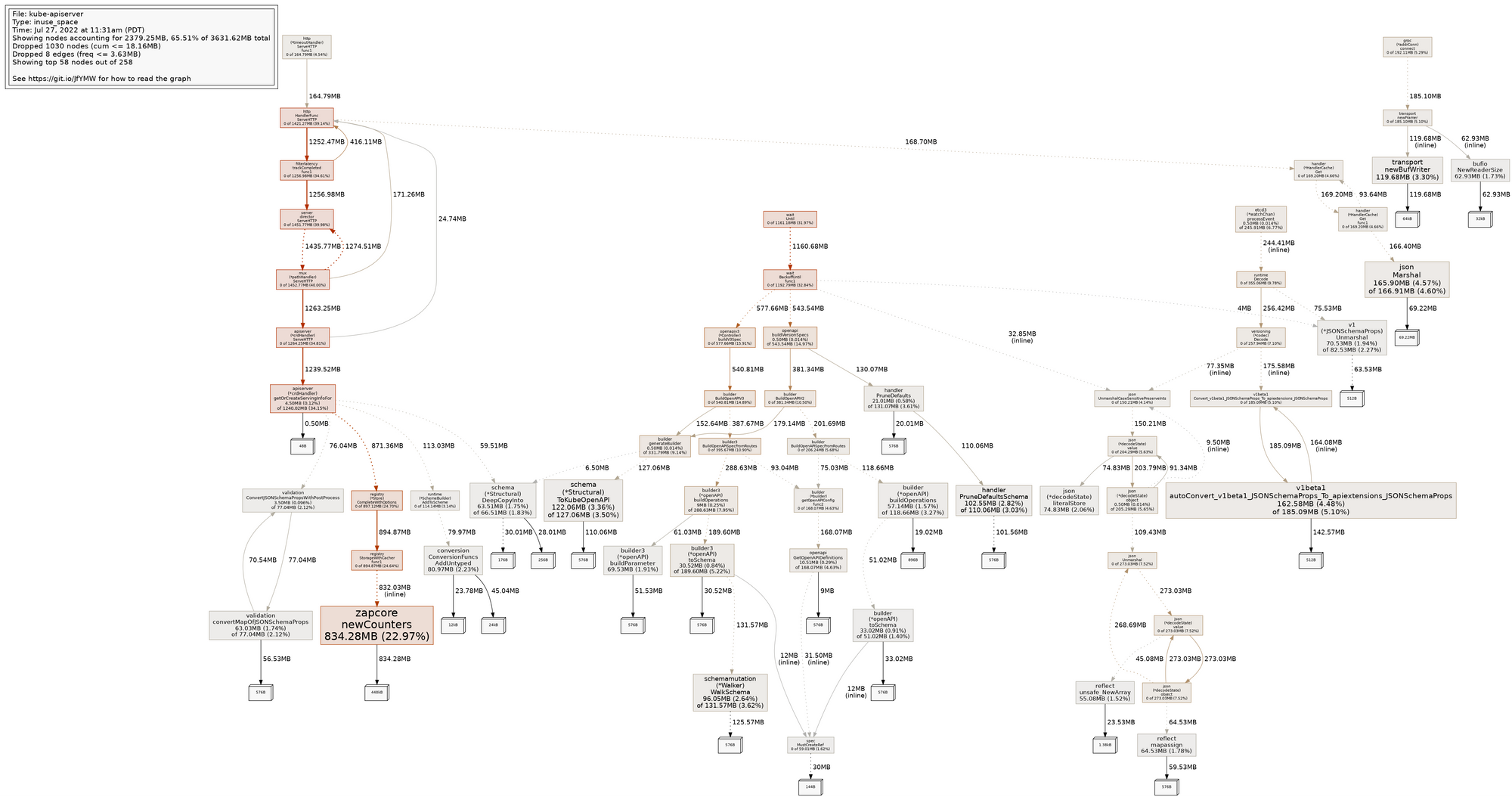
The API server actually creates an etcd client per served version of a CR (i.e. at least one etcd client per CRD), and each etcd client was instantiating its own Zap logger. This not only results in a significant memory impact from hundreds of redundant loggers, but hundreds of unnecessary TCP connections between the API server and the etcd database in which it stores its data.
Most Kubernetes API machinery maintainers seem to agree that the correct fix to this problem is to have all CR endpoints share a single etcd client. However, because we raised this issue late in the Kubernetes v1.25 release cycle we’ve opted to make a small strategic fix and simply have all etcd clients share a single logger. This fix will be included with Kubernetes 1.25 when it is released in late August, as well as the next round of patch releases for Kubernetes 1.22, 1.23, and 1.24 that will be released around the same time. We’re hopeful that this ~20% reduction in memory usage will alleviate some of the issues we’ve observed with hosted Kubernetes services.
Future Server-side Improvements
We expect that our long term efforts server-side will be focused on lowering the compute resource cost of a CRD. In the more immediate future we’ve begun work to dramatically reduce the number of etcd clients the API server uses from one per defined CR version to one per transport (i.e. per etcd cluster). We’re also working with the GKE, EKS, and AKS engineering teams to ensure their services can handle the number of CRDs Crossplane installs.
Early investigation also shows that the API server is responsive to garbage collection tuning, with a naive experiment to trigger garbage collection when the heap grows by 50% (as opposed to the default behavior of triggering at 100% heap growth) resulting in a 25% reduction in peak RSS memory usage on an idle API server with ~2,000 CRDs installed. Further testing is required to determine whether the CPU impact of more frequent garbage collection is tolerable. Once Go 1.19 is released it may also be worth experimenting with the new memory limit setting, which provides a soft memory limit that the Go runtime will attempt to respect.
Summary
Over the last 12 months the Crossplane community has identified a new Kubernetes scaling dimension - number of defined Custom Resources - and pushed it beyond its limits. Upbound engineers have helped diagnose and remove these limits, including:
- Restrictive client-side rate-limiters.
- Slow client-side caches.
- Inefficient OpenAPI schema computation.
- Redundant, expensive, etcd clients.
Alper Rifat Uluçınar in particular has been instrumental in helping diagnose most of these issues - thank you Alper! If you found this post to be interesting you may also like his recent Kubecon talk on the subject.
If building, profiling, and optimizing cutting edge distributed systems sounds like a fun challenge (it is!), consider joining us at Upbound. We’re helping platform teams around the world to build internal cloud platforms that help them deliver amazing experiences to their own end users. We’re a global remote-first company – as of the writing of this post, Upbounders work fully remotely from 10 countries on five continents. Take a look at our open roles - we’re hiring.
Subscribe to the Upbound Newsletter